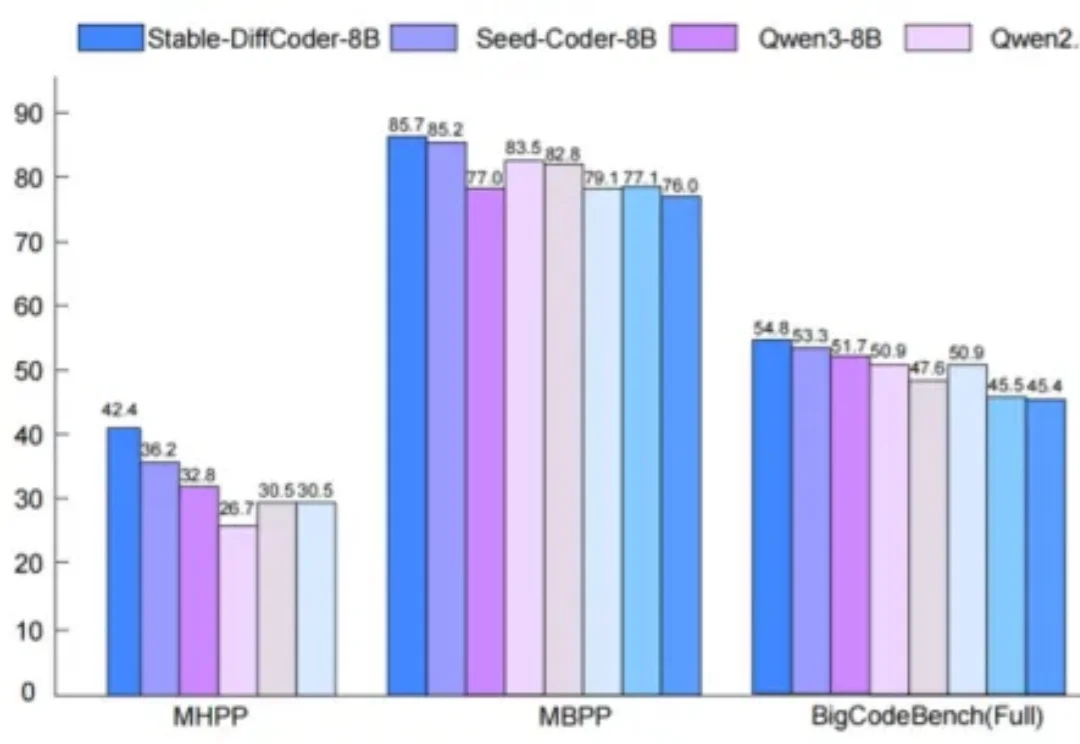
Stable-DiffCoder超越自回归模型!扩散模型在代码生成取得新突破
Stable-DiffCoder超越自回归模型!扩散模型在代码生成取得新突破扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。
来自主题: AI技术研报
11537 点击 2026-02-06 10:37
 搜索
搜索
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。
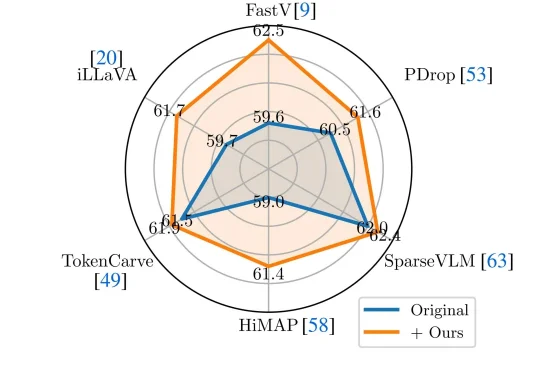
近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。

今天凌晨,喜欢闷声做大事的 DeepSeek 再次发布重大技术成果,在其 GitHub 官方仓库开源了新论文与模块 Engram,论文题为 “Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models”, 梁文锋再次出现在合著者名单中。

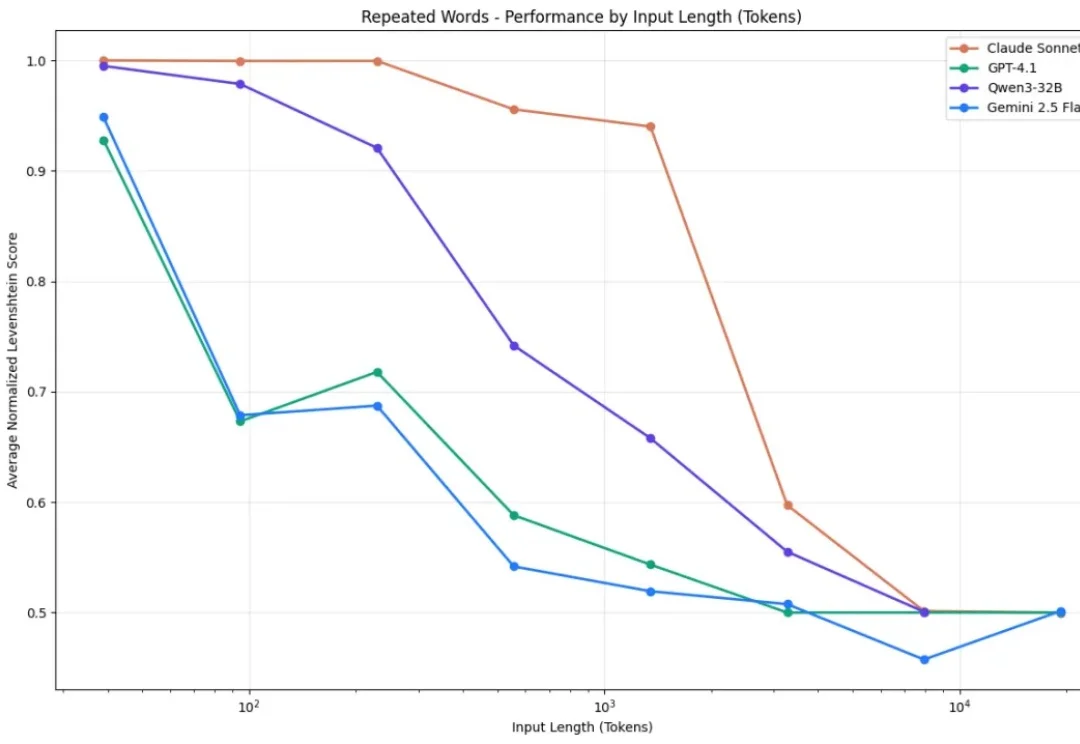
你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!
新年伊始,MIT CSAIL 的一纸论文在学术圈引发了不小的讨论。Alex L. Zhang 、 Tim Kraska 与 Omar Khattab 三位研究者在 arXiv 上发布了一篇题为《Recursive Language Models》的论文,提出了所谓“递归语言模型”(Recursive Language Models,简称 RLM)的推理策略。

近日,腾讯微信 AI 团队提出了 WeDLM(WeChat Diffusion Language Model),这是首个在工业级推理引擎(vLLM)优化条件下,推理速度超越同等 AR 模型的扩散语言模型。

扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临
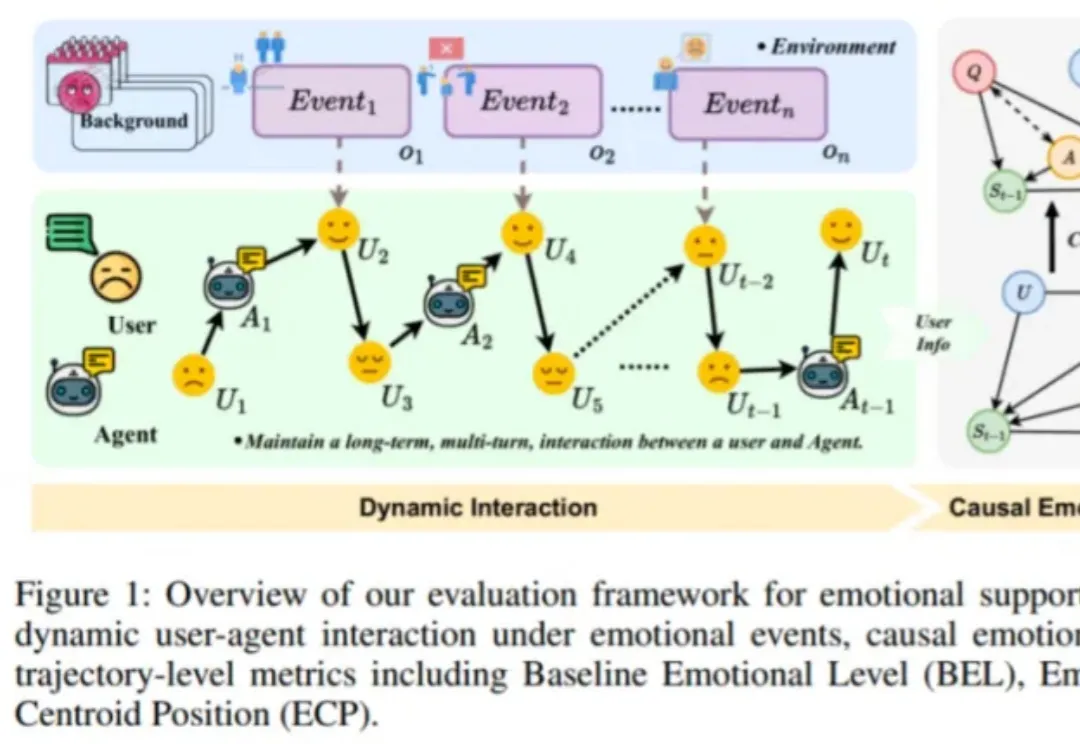
近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。

在 Vision-Language Model 领域,提升其复杂推理能力通常依赖于耗费巨大的人工标注数据或启发式奖励。这不仅成本高昂,且难以规模化。

这是一篇报告解读,原文是《DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models》